Analisis Regresi itu untuk apa?
Analisis regresi sebenarnya sangat dekat dengan teknik korelasi. Beberapa penulis seperti Pedhazur (1997) membedakan dua model ini dan cenderung memandang analisis regresi lebih superior. Terlepas dari pendapat itu, analisis regresi memang dapat memberikan informasi lebih banyak daripada korelasi, yaitu prediksi.
Salah satu hasil dari analisis regresi adalah garis regresi atau garis prediksi. Setelah kita mendapatkan garis regresi ini, kita dapat melakukan prediksi mengenai besarnya skor variabel dependen berdasarkan besarnya skor dari satu atau lebih variabel independen. Selain itu kita juga dapat mengukur seberapa tepat prediksi yang kita lakukan dengan garis prediksi yang kita dapatkan.
Jadi analisis regresi itu untuk apa? Analisis regresi dilakukan jika kita ingin mengetahui kondisi hubungan antar variabel. Biasanya satu variabel dependen dengan satu atau lebih variabel independen. Jenis data dari variabel dependen biasanya berupa data kontinum. Sementara jenis data dari variabel independen dapat berupa data kontinum maupun kategorik. Analisis regresi juga dilakukan jika kita ingin mendapatkan garis regresi untuk melakukan prediksi dan memperoleh informasi mengenai seberapa baik prediksi dilakukan dengan garis tersebut.
Artikel ini akan membahas materi mengenai analisis regresi sederhana, yaitu hubungan antara satu variabel dependen dengan satu variabel independen. Konsep mengenai analisis regresi sederhana ini dapat diterapkan ke analisis regresi dengan lebih dari satu variabel independen. Analisis regresi dengan lebih dari satu variabel independen akan dibahas dalam postingan sendiri.
Scatter Plot
Jika kita membicarakan korelasi atau regresi sederhana, kita tidak dapat melepaskan diri dari scatter plot. Scatter plot berupa grafik yang menggambarkan hubungan antara dua variabel. Sesuai namanya, scatter plot berisi titik-titik (plots) yang tersebar (scatter) dalam suatu grafik. Penentuan posisi satu titik didasarkan pada besarnya nilai dari variabel independen dan dependen. Biasanya variabel independen akan digambarkan dengan sumbu x sementara variabel dependen pada sumbu y.
Baiklah, untuk lebih jelasnya kita lihat contoh berikut:
Tabel 1.
Data Kasus
 Tabel 1. merupakan data dari sepuluh orang siswa yang diberi tes numerik dan kemudian dilihat nilai ulangan matematikanya. Jika dilihat sepintas rasanya kedua data itu saling terkait. Hmm…. Bagaimana jika kita lihat scatter plotnya saja? Begini caranya:
Tabel 1. merupakan data dari sepuluh orang siswa yang diberi tes numerik dan kemudian dilihat nilai ulangan matematikanya. Jika dilihat sepintas rasanya kedua data itu saling terkait. Hmm…. Bagaimana jika kita lihat scatter plotnya saja? Begini caranya:Kedua, kita buat skala untuk tiap sumbu dimulai dari nilai terkecil untuk tiap variabel dikurangi 1. Jadi misalnya untuk variabel tes numerik, yang akan menjadi sumbu X, kita mulai sumbu X ini dengan angka 5.
Ketiga, kita letakkan setiap poin dalam grafik tersebut berdasarkan nilainya pada sumbu X dan sumbu Y. Misalnya untuk poin pertama, kita meletakkan pada grafik dengan koordinat (6,7).
Hasil dari grafik tersebut adalah scatter plot seperti yang terlihat pada gambar 1. berikut:
Gambar 1.
Scatter Plot
Scatter Plot
 Jika dilihat sepintas kita bisa melihat bahwa titik-titik tersebut memiliki pola yang cenderung naik. Ini berarti semakin besar nilai variabel independen, nilai variabel dependen juga akan naik. Ya… ya ini berarti ada korelasi yang positif antara variabel independen dan variabel dependen. Jika kita hitung angka korelasinya menggunakan rumus korelasi product momen, kita akan mendapatkan angka 0.446.
Jika dilihat sepintas kita bisa melihat bahwa titik-titik tersebut memiliki pola yang cenderung naik. Ini berarti semakin besar nilai variabel independen, nilai variabel dependen juga akan naik. Ya… ya ini berarti ada korelasi yang positif antara variabel independen dan variabel dependen. Jika kita hitung angka korelasinya menggunakan rumus korelasi product momen, kita akan mendapatkan angka 0.446.Well, selesai sudah tugas kita jika ketertarikan kita hanya ingin melihat keeratan hubungan antar variabel. Tetapi jika kita ingin melakukan prediksi variabel dependen dari variabel independennya, kita membutuhkan informasi lebih banyak dari ini, informasi mengenai garis regresi yang dinyatakan dalam bentuk persamaan Prediksi Y=a +bX. Prediksi Y adalah prediksi variabel dependen dengan menggunakan informasi dari variabel dependen, a merupakan intercept, b merupakan slope.
Garis Regresi
Jadi bagaimana kita mendapatkan garis regresi ini? Sebenarnya kalau pertanyaannya hanya sampai di sana, jawabannya mudah. Buat saja sebuah garis yang menurut kita mewakili scatter plot dalam gambar 1. “Yang manapun?” tanya seseorang mungkin. “Ya yang manapun”, jawab saya. Loh tapi kok di buku-buku itu rumus-rumusnya beribet banget?
Karena dalam buku-buku tersebut, garis regresi yang ingin didapatkan harus memiliki kriteria khusus. Garis regresi ini harus menghasilkan kesalahan prediksi paling kecil dibandingkan semua garis regresi yang mungkin dibuat.
“Kesalahan prediksi?”
Ya kesalahan prediksi. Tentu saja kita menginginkan prediksi kita tepat 100%, namun demikian dalam dunia nyata sulit sekali mendapatkan ketepatan prediksi sesempurna itu. Oleh karena itu pasti akan ada kesalahan prediksi. Misalnya kita buat saja sebuah garis regresi Prediksi dari Y=2*X. Jika ini diterapkan pada data kita sebelumnya, maka hasilnya akan seperti di tabel 2.
Tabel 2.
Tabel hasil prediksi dan kesalahan prediksi Y dari X
Tabel hasil prediksi dan kesalahan prediksi Y dari X
 Prediksi dari Y adalah hasil perhitungan menggunakan garis prediksi yang kita tetapkan. Y – prediksi Y merupakan kesalahan prediksi yang kita lakukan jika kita menggunakan garis regresi yang kita tetapkan tadi.
Prediksi dari Y adalah hasil perhitungan menggunakan garis prediksi yang kita tetapkan. Y – prediksi Y merupakan kesalahan prediksi yang kita lakukan jika kita menggunakan garis regresi yang kita tetapkan tadi.Nah, tiap garis prediksi yang mungkin dibuat tentu saja memiliki kemungkinan salah prediksi. Dari semua garis prediksi yang mungkin dibuat, kita memilih satu yang menghasilkan kesalahan prediksi terkecil.
“Sebentar…sebentar… apa ini berarti kita harus menggambar banyak garis prediksi?”
Ya! Hehe…maaf bercanda… tidak kok. Kita tidak harus menggambar semua garis prediksi itu dan menghitung satu-satu seperti tadi. Ada sebuah teknik estimasi untuk mencari garis prediksi terbaik dalam arti memiliki kesalahan prediksi terkecil, yaitu Least Square Estimation atau sering dikenal dengan Ordinary Least Square. Dalam hal ini yang ingin dicari adalah garis prediksi yang menghasilkan jumlah kesalahan prediksi terkecil dalam bentuk kuadrat atau dirumuskan seperti ini:
 “Tapi ini masih berarti kita perlu mencari nilai ini untuk setiap garis… ini berarti kita masih tetap perlu menghitung satu-satu…”
“Tapi ini masih berarti kita perlu mencari nilai ini untuk setiap garis… ini berarti kita masih tetap perlu menghitung satu-satu…”Tenang… tenang…Kita akan menghitung satu-satu seandainya di dunia ini tidak ada Calculus.
“Bagaimana mungkin tokoh komik temannya Tintin menyelesaikan masalah ini?”
Sabar… sabar… yang saya maksud bukan tokoh komik, tapi calculus dalam matematika. Dengan memanfaatkan calculus kita dapat mencari garis regresi yang akan memberikan nilai kesalahan prediksi kuadrat yang terkecil. Di sini saya tidak akan cerita bagaimana si calculus bekerja, tetapi dengan menggunakan calculus ini ditemukan bahwa ternyata garis regresi akan menghasilkan kesalahan prediksi kuadrat terkecil jika
 Yaitu jika Prediksi dari Y merupakan mean dari Y untuk setiap nilai dari X. Mean yang dimaksud di sini adalah mean populasi. Inilah sebabnya mengapa Ordinary Least Square regression juga sering disebut sebagai conditional mean regression, atau teknik regresi yang didasarkan pada mean kondisional, atau mean dari Y untuk setiap nilai X.
Yaitu jika Prediksi dari Y merupakan mean dari Y untuk setiap nilai dari X. Mean yang dimaksud di sini adalah mean populasi. Inilah sebabnya mengapa Ordinary Least Square regression juga sering disebut sebagai conditional mean regression, atau teknik regresi yang didasarkan pada mean kondisional, atau mean dari Y untuk setiap nilai X.Parameter-Parameter Garis Regresi
Lalu bagaimana rumus untuk menemukan garis regresi yang akan menghasilkan kesalahan prediksi kuadrat yang terkecil?
Kita perlu mencari satu demi satu parameter dari garis regresi kita. Parameter-parameter yang saya maksud adalah intercept dan slope seperti yang telah saya sebutkan di atas.
Intercept merupakan konstanta dalam persamaan regresi. Intercept sering dilambangkan sebagai a atau b0, yang merupakan nilai dari prediksi Y jika nilai dari X adalah nol (X=0). Intercept dapat memiliki makna praktis dalam suatu penelitian, tetapi dalam penelitian lain hanya memiliki makna matematik saja. Misalnya dalam suatu penelitian untuk menghubungkan jumlah jam latihan fisik dengan peningkatan berat badan per minggu ditemukan intercept sebesar 0.4 gram. Ini berarti jika seseorang tidak melakukan latihan fisik sama sekali, ia akan mengalami peningkatan sebesar 0.4 gram per minggu. Tetapi dalam contoh kasus kita, misalnya ditemukan intercept sebesar 0.5 tidak dapat dikatakan bahwa jika seseorang tidak memiliki kemampuan numerik, maka nilai matematika nya akan sama dengan 0.5. Dalam kasus terakhir, intercept hanya memiliki makna matematis saja.
Slope merupakan tingkat kemiringan garis regresi, yang juga berarti berapa banyaknya peningkatan Y jika X meningkat sebanyak 1 poin. Misalnya saja dalam persamaan Y = 2X, ini berarti peningkatan 1 poin dari X akan diikuti peningkatan sebanyak 2 poin dari Y.
Lalu bagaimana menghitung kedua parameter ini?
Untuk menghitung Slope kita gunakan rumus ini:
 Dapat dilihat di sini bahwa rumus mencari slope ini mirip sekali dengan rumus mencari korelasi product momen. Bedanya terletak pada penyebutnya. Pada rumus korelasi, KovarianXY dibagi standard deviasi dari X dan standard deviasi dari Y, sementara ketika menghitung slope, kita membagi kovarian ini dengan varian dari X.
Dapat dilihat di sini bahwa rumus mencari slope ini mirip sekali dengan rumus mencari korelasi product momen. Bedanya terletak pada penyebutnya. Pada rumus korelasi, KovarianXY dibagi standard deviasi dari X dan standard deviasi dari Y, sementara ketika menghitung slope, kita membagi kovarian ini dengan varian dari X.Sementara untuk menghitung intercept kita menggunakan rumus ini:
 Baiklah kita bisa menggunakan contoh tadi untuk ilustrasinya.
Baiklah kita bisa menggunakan contoh tadi untuk ilustrasinya. Jadi kita temukan b = 0.217 ini berarti peningkatan sebanyak 1 poin pada kemampuan numerik, akan diikuti dengan peningkatan sebanyak 0.217 poin pada nilai matematika. Dan intercept sebesar a = 6.471 yang dalam kasus ini tidak memiliki makna praktis. Jika digambar, garis regresi yang kita dapatkan itu akan terlihat seperti gambar 2. Garis regresi inilah yang memiliki tingkat kesalahan prediksi kuadrat yang paling kecil.
Jadi kita temukan b = 0.217 ini berarti peningkatan sebanyak 1 poin pada kemampuan numerik, akan diikuti dengan peningkatan sebanyak 0.217 poin pada nilai matematika. Dan intercept sebesar a = 6.471 yang dalam kasus ini tidak memiliki makna praktis. Jika digambar, garis regresi yang kita dapatkan itu akan terlihat seperti gambar 2. Garis regresi inilah yang memiliki tingkat kesalahan prediksi kuadrat yang paling kecil.Gambar 2.
Garis regresi dari data kasus
 R2 dan Signifikasi Parameter-Parameter
R2 dan Signifikasi Parameter-Parameter“Apakah pekerjaan kita sudah beres? Kan kita sudah menemukan garis prediksinya?”
Sayang sekali belum. Kita masih harus melakukan beberapa perhitungan terkait dengan seberapa baik garis regresi kita melakukan prediksi dan apakah parameter yang kita dapatkan ini berbeda dari nol di populasi atau signifikan.
Untuk urusan yang pertama, terkait dengan seberapa baik garis regresi kita melakukan prediksi, kita dapat menggunakan nilai R2 yang sering disebut juga sebagai Sumbangan Efektif. Dalam kasus ini, kita hanya meregresikan satu variabel dependen pada satu variabel independen, oleh karena itu nilai R2 bisa didapatkan dengan secara langsung mencari kuadrat dari korelasi antara kedua variabel tersebut. Nilai korelasi product momen dari kedua variabel tersebut adalah 0.446. Angka ini tinggal dikuadratkan saja menjadi 0.199 yang berarti 19.9% variasi dari variabel dependen dapat dijelaskan oleh variabel independen. Angka inilah yang menggambarkan seberapa baik prediksi dilakukan oleh garis regresi. Semakin mendekati 100% makin baik. Memang dalam penelitian-penelitian di psikologi jarang ditemukan R2 yang besar. Angka 19.9% biasanya dianggap sudah cukup memuaskan.
Berikutnya terkait dengan apakah kita dapat menyimpulkan bahwa parameter-parameter di populasi tidak sama dengan nol? Apakah b di populasi dan a di populasi tidak sama dengan nol. Untuk mengecek hal ini, pertama yang perlu dilakukan adalah menghitung nilai F yang menguji secara keseluruhan parameter-parameter ini. Nilai F ini juga dapat digunakan untuk menguji apakah nilai R2 yang kita peroleh juga signifikan.
Jadi bagaimana melakukannya?
Pertama, kita perlu menghitung JK Regresi, JK dalam dan JK Total. Seperti Anova ya? Ya memang benar. Langkah-langkah yang dilakukan memang seperti anova karena kita juga akan melakukan uji F di sini (Bahkan sebenarnya Regresi dan Anova merupakan saudara dekat). Rumus untuk setiap JK dapat dilihat sebagai berikut:
 “Sebentar…sebentar…. Rumus JK dalam ini seperti ….seperti…”
“Sebentar…sebentar…. Rumus JK dalam ini seperti ….seperti…”Ya… ya …. JK dalam itulah kesalahan prediksinya dalam bentuk kuadrat.
Ketiga JK ini akan distandardkan dengan membaginya dengan db masing-masing yang rumusnya sebagai berikut:
 Hasil pembagian JK dengan db ini akan menghasilkan nilai MK (Mean Kuadrat). Nilai F didapatkan dari pembagian MK regresi dengan MK dalam atau :
Hasil pembagian JK dengan db ini akan menghasilkan nilai MK (Mean Kuadrat). Nilai F didapatkan dari pembagian MK regresi dengan MK dalam atau : Nah, nilai F ini yang kemudian kita konsultasikan ke tabel F untuk dicek signifikasinya.
Nah, nilai F ini yang kemudian kita konsultasikan ke tabel F untuk dicek signifikasinya.Baiklah kita kerjakan contoh kasus kita supaya jelas penerapan rumus-rumus ini ya. Saya membuat lagi sebuah tabel yaitu Tabel 4 untuk membantu ilustrasi hitungan dalam kasus ini.
Tabel 4.
Ilustrasi hitungan.
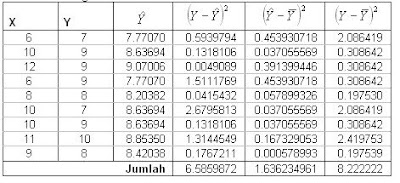 Dalam ilustrasi tersebut prediksi dari Y ( ) dihitung menggunakan garis regresi yang sudah kita dapatkan yaitu Y=6.471+0.217*X. Baris paling akhir, yaitu baris jumlah, merupakan nilai JK dari JK dalam, JK regresi dan JK Total berturut-turut. Kita bisa amati juga bahwa JK dalam +Jk regresi akan sama dengan JK Total.
Dalam ilustrasi tersebut prediksi dari Y ( ) dihitung menggunakan garis regresi yang sudah kita dapatkan yaitu Y=6.471+0.217*X. Baris paling akhir, yaitu baris jumlah, merupakan nilai JK dari JK dalam, JK regresi dan JK Total berturut-turut. Kita bisa amati juga bahwa JK dalam +Jk regresi akan sama dengan JK Total.
Ilustrasi hitungan.
 Dalam ilustrasi tersebut prediksi dari Y ( ) dihitung menggunakan garis regresi yang sudah kita dapatkan yaitu Y=6.471+0.217*X. Baris paling akhir, yaitu baris jumlah, merupakan nilai JK dari JK dalam, JK regresi dan JK Total berturut-turut. Kita bisa amati juga bahwa JK dalam +Jk regresi akan sama dengan JK Total.
Dalam ilustrasi tersebut prediksi dari Y ( ) dihitung menggunakan garis regresi yang sudah kita dapatkan yaitu Y=6.471+0.217*X. Baris paling akhir, yaitu baris jumlah, merupakan nilai JK dari JK dalam, JK regresi dan JK Total berturut-turut. Kita bisa amati juga bahwa JK dalam +Jk regresi akan sama dengan JK Total.Perhitungan berikutnya yaitu db dan MK akan saya masukkan sekaligus dalam tabel rangkuman anava dalam tabel 5.
Tabel 5.
Tabel rangkuman anava
Tabel rangkuman anava
 Karena F tabel > daripada F hitung, maka dapat disimpulkan bahwa kita gagal menolak hipotesis nol. Ini berarti R2 yang kita dapatkan di sampel besar kemungkinan hanya merupakan sampling error.
Karena F tabel > daripada F hitung, maka dapat disimpulkan bahwa kita gagal menolak hipotesis nol. Ini berarti R2 yang kita dapatkan di sampel besar kemungkinan hanya merupakan sampling error.Lalu bagaimana dengan signifikasi parameter-parameternya? Kita akan memanfaatkan uji t untuk menguji apakah parameter-parameter regresi yang kita dapatkan itu signifikan atau tidak.
Seperti yang pernah dibahas jauh sebelum ini, rumus t yang sangat umum adalah
 Dalam hal ini statistik yang menjadi perhatian adalah b, oleh karena itu rumus t-nya akan menjadi seperti ini:
Dalam hal ini statistik yang menjadi perhatian adalah b, oleh karena itu rumus t-nya akan menjadi seperti ini: Jadi mari kita terapkan dalam kasus di atas :
Jadi mari kita terapkan dalam kasus di atas : Nilai t yang kita dapatkan ini dibandingkan dengan tabel t pada df = N-2. Dalam hal ini df-nya menjadi 7. Nilai t tabel dengan taraf signifikasi 5% pada df = 7 adalah 2.3646… Dengan demikian dapat kita lihat bahwa b yang kita peroleh tidak signifikan. Atau dengan kata lain kita tidak memiliki bukti kuat untuk menyatakan bahwa nilai b di populasi tidak sama dengan nol.
Nilai t yang kita dapatkan ini dibandingkan dengan tabel t pada df = N-2. Dalam hal ini df-nya menjadi 7. Nilai t tabel dengan taraf signifikasi 5% pada df = 7 adalah 2.3646… Dengan demikian dapat kita lihat bahwa b yang kita peroleh tidak signifikan. Atau dengan kata lain kita tidak memiliki bukti kuat untuk menyatakan bahwa nilai b di populasi tidak sama dengan nol.Untuk a, rumusnya t nya tetap sama, hanya saja ada penyesuaian dengan standard deviasi dari a-nya. Rumus mencari nilai t untuk menguji a sebagai berikut:
 Jika diterapkan:
Jika diterapkan: Nilai ini juga dibandingkan dengan t tabel yang sama yaitu 2.3646. Dengan demikian dapat disimpulkan bahwa nilai a itu signifikan, atau nilai a di populasi dapat diharapkan tidak sama dengan nol.
Nilai ini juga dibandingkan dengan t tabel yang sama yaitu 2.3646. Dengan demikian dapat disimpulkan bahwa nilai a itu signifikan, atau nilai a di populasi dapat diharapkan tidak sama dengan nol.Jadi bagaimana?
Karena nilai b tidak signifikan maka dapat disimpulkan bahwa kita belum memiliki bukti yang memadai bahwa kemampuan numerik memiliki korelasi yang signifikan dengan nilai ulangan matematika. Dengan kata lain kita belum bisa memprediksi nilai ulangan dengan menggunakan skor pada tes kemampuan numerik.
Dalam kasus kita, nilai a signifikan, tapi sayangnya dalam kasus ini nilai a tidak memiliki makna praktis sehingga tidak dapat diinterpretasi dengan baik.
OK guys postingan berikutnya kita akan bicara mengenai regresi yang melibatkan lebih dari 1 variabel independen.
10 komentar :
Saya jurusan statistika...
Lagi nyari dasar teori ttg Uji levene, barlette, dan uji F.?
Kunjungi blogku.. Klik disinii
Pak, salam kenal...saya sedang menyelesaikan thesis saya dan menggunakan metode kuantitatif untuk penelitian saya. saya sedang meneliti mengenai korelasi antara faktor-faktor kesuksesan suatu proyek dengan suatu implementasi kesuksesan. yang saya masih bingung pak, pada tahap mana kita bisa sebut itu hanya korelasi dan pada tahap mana kita harus melakukan analisis regresi...saya sudah membaca tulisan2 di blog bapak tapi masi bingung juga hehe...
mohon pencerahannya pak
Hai harti,
Saya pikir pilihan antara regresi dan korelasi dilakukan berdasarkan pertinmbangan apakah peneliti akan melakukan prediksi atau tidak.
Jika peneliti memang bermaksud melakukan prediksi, maka analisis regresi dapat digunakan, sementara jika peneliti hanya ingin melihat keeratan hubungan antara dua variabel cukup menggunakan korelasi saja.
Saya Ahmad, mau bertanya apakah salah satu asumsi analsis regresi adalah teknik pengambilan sampelnya harus random?
Halo Ahmad,
sebenarnya semua analisis inferensial mensyaratkan pengambilan sampel random. Ini agar hasil estimasi nilai p dapat berlaku sesuai dengan nilai yang dilaporkan.
Hanya saja memang pengambilan sampel secara random ini seringkali tidak mudah. Oleh karena itu orang cenderung menggunakan sampel non-random. Nah, kelemahan inilah yang sebenarnya perlu diwaspadai ketika peneliti hendak melakukan interpretasi hasil analisisnya.
pak kalau saya hanya melakukan uji korelasi (tidak melakukan regresi) apakah saya perlu menghitung R2? terimakasih
pak, salam kenal...
kemarin saya baru saja ujian pendadaran,,, lalu ditanya apabila kedua variabel bebas itu ternyata setelah di uji saling dependen, apa yang harus dilakukan???
kiranya bapak bisa membantu saya menyelesaikan masalah ini, saya ucapkan terimakasih
untuk b3be,
Jawabannya tergantung pada pertanyaan apa yang hendak dijawab oleh penelitian anda. Kalau ingin mengetahui sumbangan dari variabel satu ke variabel lain maka tentunya perlu dihitung r kuadrat. Tetapi jika kepentingan penelitian hanya sampai mengetahui derajat hubungan, maka angka koefisien korelasi sudah mencukupi.
Hanya saja mungkin ada beberapa orang yang merasa informasi yang disediakan oleh r , kurang banyak sehingga perlu dilengkapi dengan r kuadrat.
Untuk anonim,
saya merasa kurang jelas apa yang ditanyakan. Apakah maksudnya ada multikolinearitas yang besar?
Jika memang demikian, maka peneliti memang harus mengecek apakah ada kekeliruan dalam memasukkan data sehingga terjadi multikolinearitas (khususnya jika menyangkut variabel dummy).
Jika tidak, maka salah satu variabel harus di'drop' dan dianggap dua variabel tersebut sebenarnya representatif satu sama lain.
Demikian jawaban sementara saya, ada baiknya pertanyaan tersebut dielaborasi agar saya lebih memahami konteksnya.
Makasih pencerahannya
Bagi yang memiliki online shop dan ingin membuat website toko online lengkap, desain menarik, gratis penyebaran, SEO, Backlink, agar usaha nya mudah ditemukan banyak pembeli di internet, sehingga bisa meningkatkan penjualan, klik ya : www.jasabuattokoonline.com
Medium : Jasa Pembuatan Website Toko Online - Tokopedia : Jasa Website Toko Online dan Website Toko Online Murah - Facebook : Jasa Pembuatan Toko Online
www.jilbabterbaru.my.id
Posting Komentar